

AI for bio needs real-time data
On the importance of time in biology

Large language models (LLMs) have ushered in a new wave of AI hype. However, when applied to problems in biology, results have been mixed. One reason that AI is failing to translate to the clinic is because we traditionally collect biological data on very sparse timescales. Using such sparse data would be like training LLMs on every 10th word in a sentence. So why haven’t we made better progress here?
The open secret is that until now, we haven’t had the technology to collect continuous human data at scale. We’ve used static images and measurements of biology across sparse and inconsistent timepoints, much of which is from animals, as the next best thing. Cutting through the AI hype, there is one thing to keep in mind: both life and disease are processes that occur over time. It follows that AI for biology needs real-time human data to match.

An essay series on cancer as a system error
In part 2 of this 5 part series, we’re exploring the untapped potential in the data generated from therapeutic neurotechnology. As a quick refresh, in part 1 we discussed how thinking about biology like a reducible machine may be leading us astray. By using a reductionist framework, we make the implicit assumption that the way to ‘solve’ biology is by elucidating all the components. But as we know, putting all these biological ‘ingredients’ into a bowl and mixing won’t build you a body. How do the components organize, collaborate, and evolve?
While the majority of researchers would agree that the dynamics of the system matter, without the tools or data to explore this, most AI for biology today has excluded this key dimension. Neurotechnology fills this much needed gap. High fidelity continuous recordings from humans coupled with increased computing power set the stage for an overhaul in how we can use machine learning in biology.
In the case of cancer, the next stepwise improvement in survival is likely to come from interfacing with the nervous system—the master control system of human biology. As conflicting evidence accumulates on the genetic origins of cancer, the world is turning to a more holistic understanding of the disease, and how it depends on its environment and time. Rather than reduce it to its ‘simplest’ parts, we want to learn the behavior of the system. That is, how cancer hijacks functional electrical signaling throughout the body to grow and spread. From there, we can modulate it to correct system malfunction without the need for reduction.
Why static, bottom-up approaches are hitting a wall
LLMs are trained on enormous amounts of data in a self-supervised way so that they learn patterns and structure. Importantly, they are not explicitly taught the fine details of language in order to write correct sentences, or how computer code should be written in order for it to execute correctly. In other words, these models are built from the top-down. Only the architecture, learning rule, and cost function are specified, and not the exact details of how the model should perform certain tasks.
When applied to biology, AI is certainly making an impact on paper. Though it’s not just LLMs doing the work, and the data we have to train these models consists almost unanimously of sparse time points. Whether the current approaches will translate to the clinic brings us back to our central question—what about dynamics? What about how the system changes over time?
Take Alpha Fold, which has dramatically improved protein structure prediction, or computer vision models, which can detect cancer from MRI images faster than a human. Without doubt, applying AI to biology has sped up and improved what used to take humans much more time to do. Though still looming is the question of whether it translates to interventions in reality that actually work, beyond replacing tasks we used to do, only faster.
Historically, models for biology have been built from the bottom up using more of a reductionist approach. While this approach has yielded insight, we are now hitting a ceiling of complexity of these models that is proving hard to crack.
The reason for this is that biological processes evolve across vast spatial and temporal scales. Capturing processes that occur across these scales will be near impossible using a classical reductionist approach. Yet, we need to bridge these multiple scales to reach the next-generation of breakthroughs in disease detection and intervention. With the right data, i.e., continuous data, the top down approach of training AI models lets us naturally bridge these scales. Moreover, training models on vast amounts of biological data, like continuous brain recordings, will likely unlock totally new classes of AI models that may be self adaptive (i.e., learn and adapt in real time to new inputs) and process information to make decisions more akin to humans.
Biology is highly dynamic and heterogeneous
A problem with using AI to model biological processes is that our biology is always changing. The brain is perhaps the most striking example of this. Neurons, their activity, and their synaptic connections are constantly evolving. Diseases such as Epilepsy, Parkinson’s, or brain cancer all evolve across time. However, most biological datasets are only static snapshots like blood draws months apart or MRI imaging every 3–6 months.
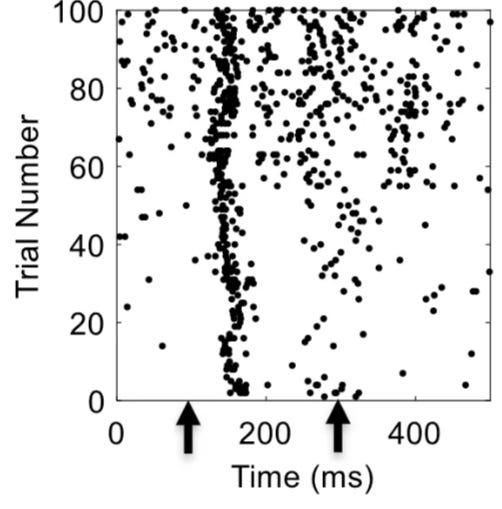
Importantly, not only does the biological data we record change over time, it can also be vastly different from person to person too! No two brains are the same. For example, if you present exactly the same stimulus to two people even in an extremely controlled experimental setting, you will elicit very different patterns of neural activity. In fact, even if you repeatedly present the same stimulus to the same person, you will observe different patterns of neural activity each time the stimulus is presented (Figure 1). Such changes in neural responses over time are called neural drift. Taken together, we’ll almost certainly need patient-specific, real-time data if we want to crack some of the toughest problems in biology.
Another issue is that time-point measurements can make normal daily variation appear abnormal, often driving incorrect conclusions. Even day–night cycles strongly affect many biological processes and impact how people respond to treatment (indeed ‘chronotherapeutics’ for diseases such as Parkinson’s disease are an active field of research). Take blood tests that measure cortisol—which is known to vary significantly over the day. It’s not practical to measure cortisol continuously, and blood tests are often months or years apart. What might we miss in between two measurements? How can we expect a model to be useful unless it is trained on the time-resolved data it needs?
A fascinating example of the importance of time in medicine arrived quite recently. In advanced Non-small-cell lung cancer (NSCLC), a study demonstrated that giving immunotherapy in the morning led to a ~13 percentage point increase in survival probability 4 years in.
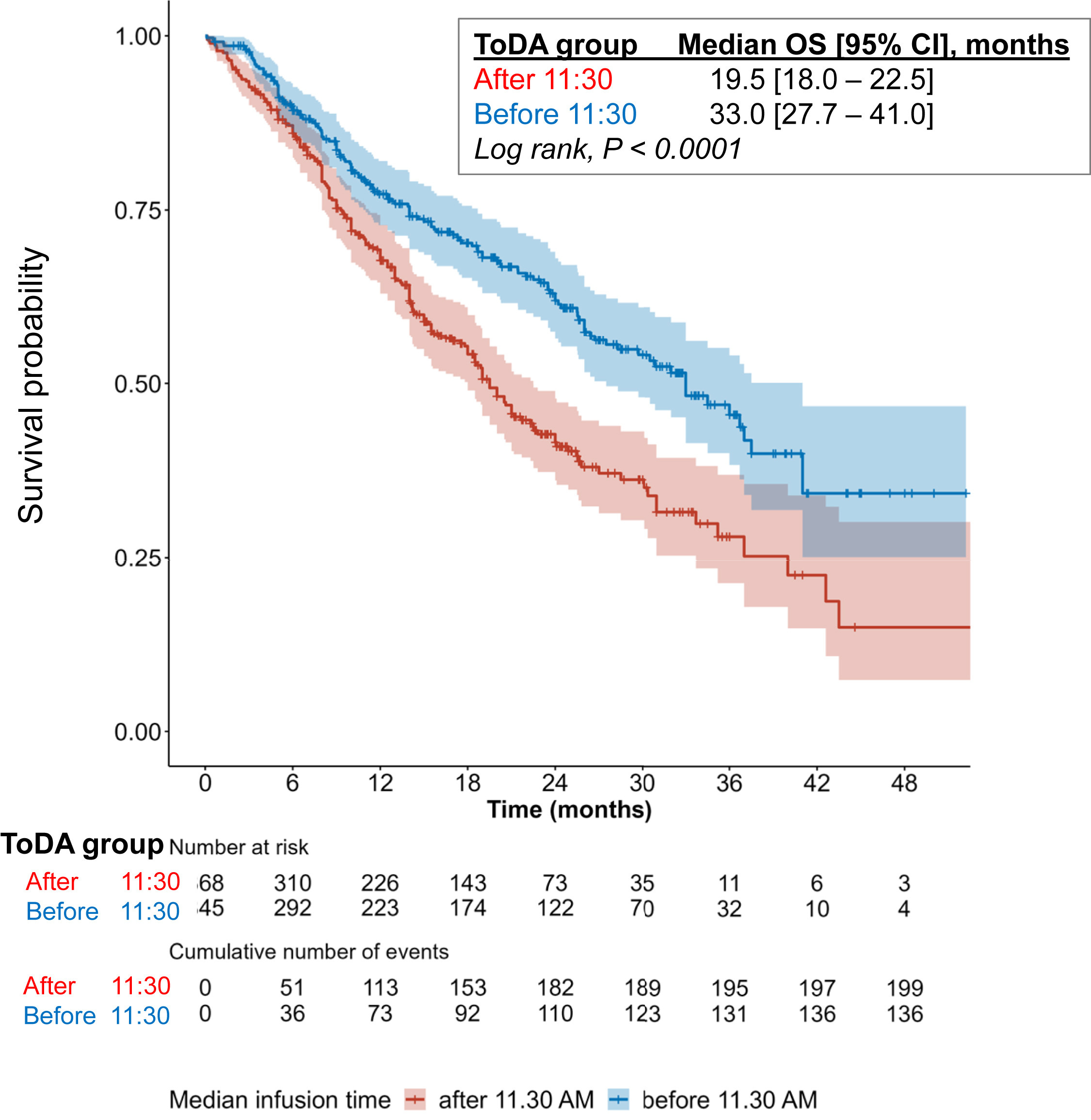
Such a profound result from something as simple as time-of-day drew immediate skepticism. It must be more complicated than that, right? Though digging deeper, such results have been observed in other cancers too. Another study demonstrated a similar survival benefit in kidney cancer, reigniting a long-sidelined discussion on the role of the circadian rhythm in regulating the immune system. Of course, such results would be discovered much faster if cancer patients were wearing continuous monitors.
Altogether, this implies that models of biological systems likely also need to update over time to continue to be accurate. While reductionist models like virtual cells and protein structure prediction may remain valuable for discovery, when it comes to early detection and intervention, we will need a different approach; one that uses real-time, patient-specific data to capture how conditions evolve in situ.
Enter neurotechnology: the missing data layer
Therapeutic neurotechnologies and brain computer interfaces (BCIs) are already proving to be transformative for conditions such as Parkinson’s and Epilepsy. Still, some find the concept of an implant intimidating. Fortunately, we have models from history for how public perception evolves.
Take the pacemaker. Much like neurotechnology today, the public was a little uneasy when the pacemaker was introduced in the 1950s. The idea of a surgical implant in a vital organ was naturally frightening. Yet contrast this to today, where ~3 million people in the US have a pacemaker and the procedure is routine. Unlike drugs, implants are one of the most effective ways to manage disease given adherence to treatment is 100% and localized, meaning less unintended side effects. Much like we know that the roads would be safer if all vehicles were autonomous, implants remove the role of human-error.
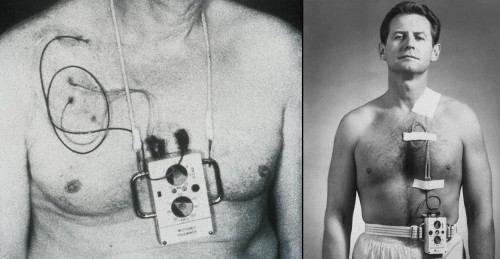
Neurotechnology is following a similar path. That is, in the near future, we expect neural implants will be commonplace in treating a plethora of brain and nervous system diseases and disorders.
Imagine a world where every implanted therapeutic device doubles as a continuous data generator. Each patient’s real-time brain recordings will not only improve their own treatment (e.g., via closed-loop neuromodulation or adaptive stimulation), but will also advance early detection and intervention models. These are technologies that become more insightful the more we use them.
Think of this like Google Maps for biology. You don’t just want a map of the roads, which might represent the connections between neurons. You want to know where the traffic is right now, how it’s changing, and how to reroute in response. In the brain, both the ‘traffic’ and the ‘roads’ are changing continuously. Only by capturing that reality in real time can we create breakthroughs in early disease detection and intervention. Access to such real-time, high-fidelity neural data is now possible with implantable neurotechnologies.
Real-time data for early disease intervention and next generation AI
We’re inventing a class of cancer therapy that gets more intelligent the more we use it. Here, the real long-term value lies in how we integrate the data. Each deployed device becomes part of a learning system, building a unique dataset of human brain and nervous system activity over years. This learning system will then form the basis of a more efficient and effective healthcare infrastructure. In essence, we’re enabling:
Patient-specific closed-loop neuromodulation
Accelerated early detection models for cancer
A potential foundation for future adaptive AI models rooted in real-time, evolving human biology
For the first time in history, continuous data collection from therapeutic neurotech will allow us to integrate real-time information into how we model cancer. We are finally being faithful to what life is—a dynamic process.
Next week, our CTO, Elise Jenkins, will lay out how we can model cancer using control theory. Tying into this essay, she’ll demonstrate how real-time data from neurotechnology could be used to manage cancer in practice.
Thank you for supporting our mission
Your support helps us charge ahead to a future where we all suffer less. Please subscribe and share this essay series to help get the word out. Your comments and feedback are always welcome!
The lung cancer immunotherapy exampl is striking, a 13 percentage point survival boost just from timing. It's frustrating how much low-hanging fruit we're missing by ignoring temporal dynamics. Your Google Maps analogy captures this perfeclty, we need continuos traffic updates, not just static road maps. Do you think the main barier to adoption is technical complexity or resistance from established medical practice?